
Introduction
Apache Flink and Apache Beam are open-source frameworks for parallel, distributed data processing at scale. Unlike Flink, Beam does not come with a full-blown execution engine of its own but plugs into other execution engines, such as Apache Flink, Apache Spark, or Google Cloud Dataflow. In this blog post we discuss the reasons to use Flink together with Beam for your batch and stream processing needs. We also take a closer look at how Beam works with Flink to provide an idea of the technical aspects of running Beam pipelines with Flink. We hope you find some useful information on how and why the two frameworks can be utilized in combination. For more information, you can refer to the corresponding documentation on the Beam website or contact the community through the Beam mailing list.
What is Apache Beam
Apache Beam is an open-source, unified model for defining batch and streaming data-parallel processing pipelines. It is unified in the sense that you use a single API, in contrast to using a separate API for batch and streaming like it is the case in Flink. Beam was originally developed by Google which released it in 2014 as the Cloud Dataflow SDK. In 2016, it was donated to the Apache Software Foundation with the name of Beam. It has been developed by the open-source community ever since. With Apache Beam, developers can write data processing jobs, also known as pipelines, in multiple languages, e.g. Java, Python, Go, SQL. A pipeline is then executed by one of Beam’s Runners. A Runner is responsible for translating Beam pipelines such that they can run on an execution engine. Every supported execution engine has a Runner. The following Runners are available: Apache Flink, Apache Spark, Apache Samza, Hazelcast Jet, Google Cloud Dataflow, and others.
The execution model, as well as the API of Apache Beam, are similar to Flink’s. Both frameworks are inspired by the MapReduce, MillWheel, and Dataflow papers. Like Flink, Beam is designed for parallel, distributed data processing. Both have similar transformations, support for windowing, event/processing time, watermarks, timers, triggers, and much more. However, Beam not being a full runtime focuses on providing the framework for building portable, multi-language batch and stream processing pipelines such that they can be run across several execution engines. The idea is that you write your pipeline once and feed it with either batch or streaming data. When you run it, you just pick one of the supported backends to execute. A large integration test suite in Beam called “ValidatesRunner” ensures that the results will be the same, regardless of which backend you choose for the execution.
One of the most exciting developments in the Beam technology is the framework’s support for multiple programming languages including Java, Python, Go, Scala and SQL. Essentially, developers can write their applications in a programming language of their choice. Beam, with the help of the Runners, translates the program to one of the execution engines, as shown in the diagram below.
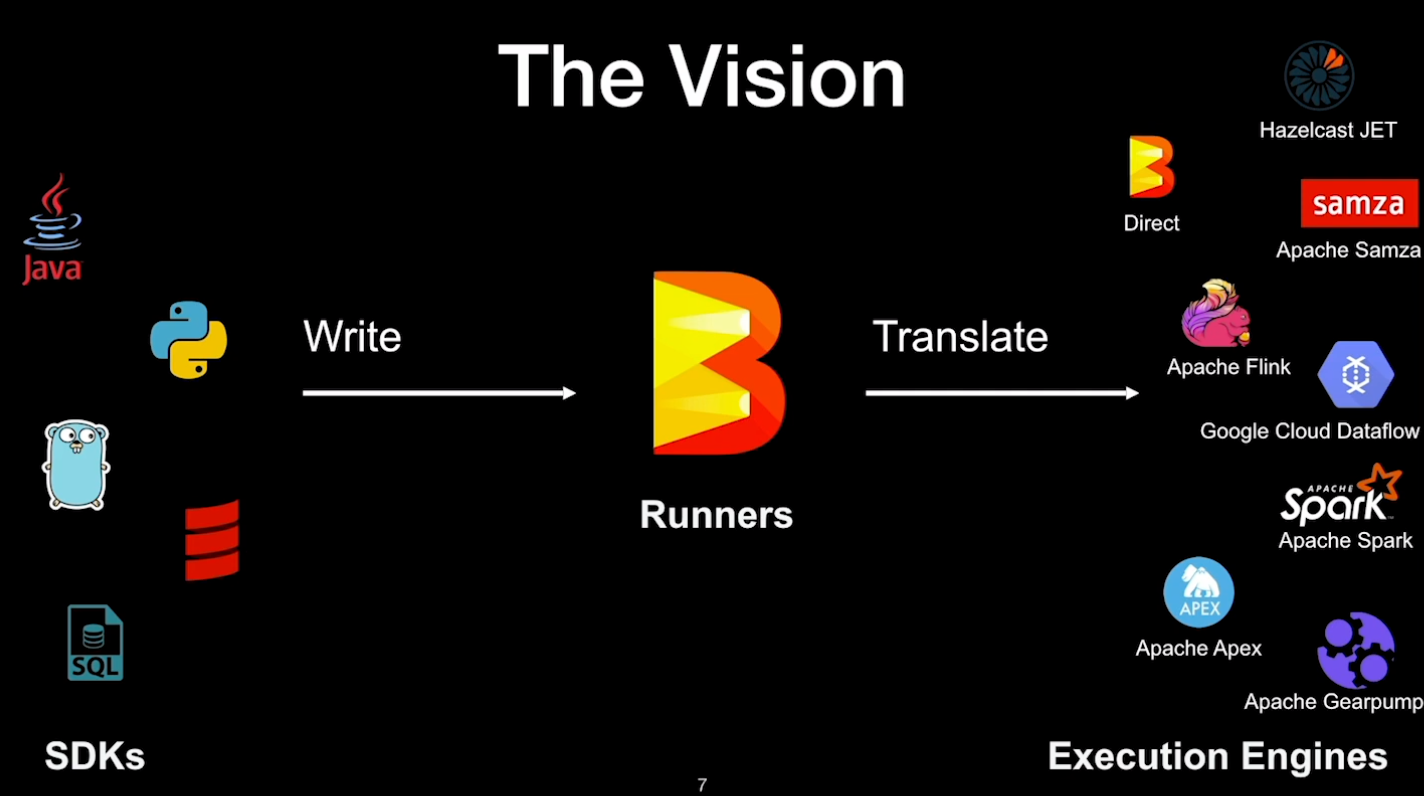
Reasons to use Beam with Flink
Why would you want to use Beam with Flink instead of directly using Flink? Ultimately, Beam and Flink complement each other and provide additional value to the user. The main reasons for using Beam with Flink are the following:
- Beam provides a unified API for both batch and streaming scenarios.
- Beam comes with native support for different programming languages, like Python or Go with all their libraries like Numpy, Pandas, Tensorflow, or TFX.
- You get the power of Apache Flink like its exactly-once semantics, strong memory management and robustness.
- Beam programs run on your existing Flink infrastructure or infrastructure for other supported Runners, like Spark or Google Cloud Dataflow.
- You get additional features like side inputs and cross-language pipelines that are not supported natively in Flink but only supported when using Beam with Flink.
The Flink Runner in Beam
The Flink Runner in Beam translates Beam pipelines into Flink jobs. The translation can be parameterized using Beam’s pipeline options which are parameters for settings like configuring the job name, parallelism, checkpointing, or metrics reporting.
If you are familiar with a DataSet or a DataStream, you will have no problems understanding what a PCollection is. PCollection stands for parallel collection in Beam and is exactly what DataSet/DataStream would be in Flink. Due to Beam’s unified API we only have one type of results of transformation: PCollection.
Beam pipelines are composed of transforms. Transforms are like operators in Flink and come in two flavors: primitive and composite transforms. The beauty of all this is that Beam only comes with a small set of primitive transforms which are:
Source(for loading data)ParDo(think of a flat map operator on steroids)GroupByKey(think of keyBy() in Flink)AssignWindows(windows can be assigned at any point in time in Beam)Flatten(like a union() operation in Flink)
Composite transforms are built by combining the above primitive transforms. For example, Combine = GroupByKey + ParDo.
Flink Runner Internals
Although using the Flink Runner in Beam has no prerequisite to understanding its internals, we provide more details of how the Flink runner works in Beam to share knowledge of how the two frameworks can integrate and work together to provide state-of-the-art streaming data pipelines.
The Flink Runner has two translation paths. Depending on whether we execute in batch or streaming mode, the Runner either translates into Flink’s DataSet or into Flink’s DataStream API. Since multi-language support has been added to Beam, another two translation paths have been added. To summarize the four modes:
- The Classic Flink Runner for batch jobs: Executes batch Java pipelines
- The Classic Flink Runner for streaming jobs: Executes streaming Java pipelines
- The Portable Flink Runner for batch jobs: Executes Java as well as Python, Go and other supported SDK pipelines for batch scenarios
- The Portable Flink Runner for streaming jobs: Executes Java as well as Python, Go and other supported SDK pipelines for streaming scenarios

The “Classic” Flink Runner in Beam
The classic Flink Runner was the initial version of the Runner, hence the “classic” name. Beam pipelines are represented as a graph in Java which is composed of the aforementioned composite and primitive transforms. Beam provides translators which traverse the graph in topological order. Topological order means that we start from all the sources first as we iterate through the graph. Presented with a transform from the graph, the Flink Runner generates the API calls as you would normally when writing a Flink job.
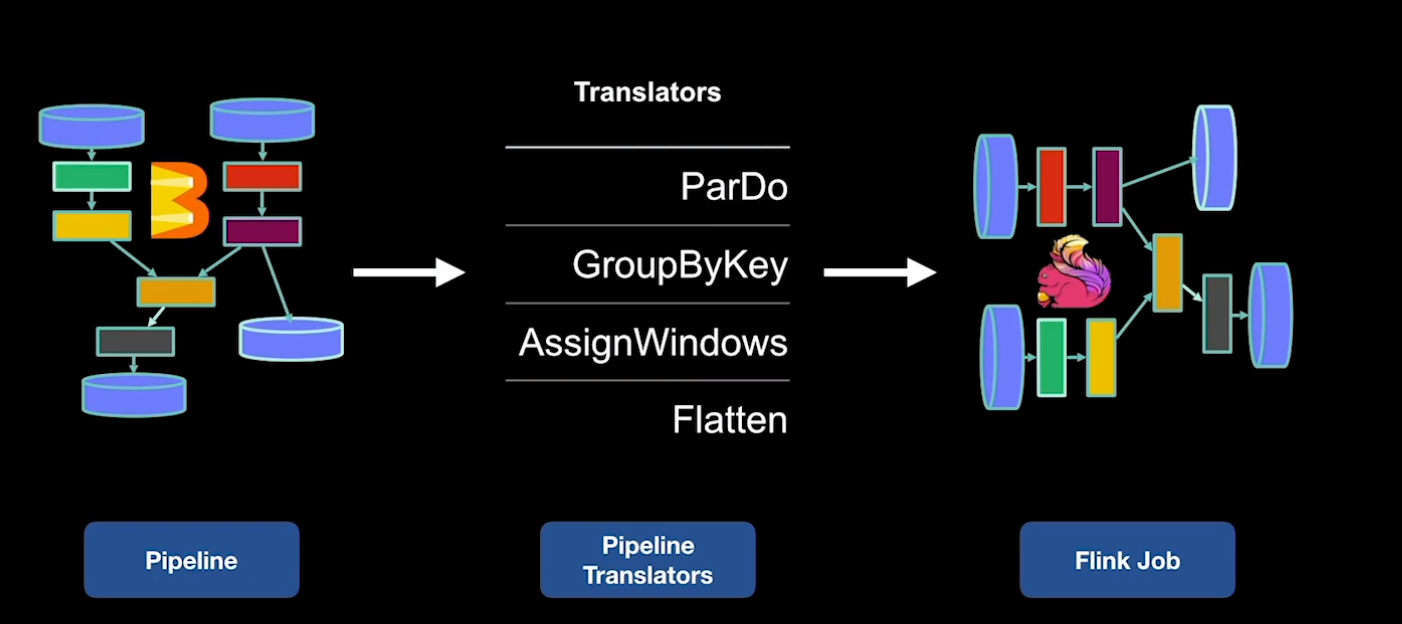
While Beam and Flink share very similar concepts, there are enough differences between the two frameworks that make Beam pipelines impossible to be translated 1:1 into a Flink program. In the following sections, we will present the key differences:
Serializers vs Coders
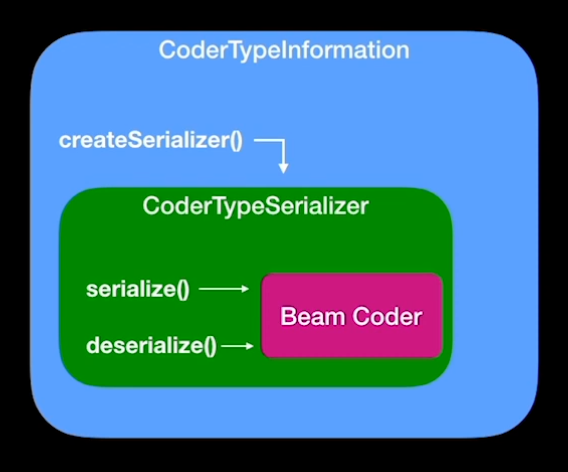
When data is transferred over the wire in Flink, it has to be turned into bytes. This is done with the help of serializers. Flink has a type system to instantiate the correct coder for a given type, e.g. StringTypeSerializer for a String. Apache Beam also has its own type system which is similar to Flink’s but uses slightly different interfaces. Serializers are called Coders in Beam. In order to make a Beam Coder run in Flink, we have to make the two serializer types compatible. This is done by creating a special Flink type information that looks like the one in Flink but calls the appropriate Beam coder. That way, we can use Beam’s coders although we are executing the Beam job with Flink. Flink operators expect a TypeInformation, e.g. StringTypeInformation, for which we use a CoderTypeInformation in Beam. The type information returns the serializer for which we return a CoderTypeSerializer, which calls the underlying Beam Coder.
Read
The Read transform provides a way to read data into your pipeline in Beam. The Read transform is supported by two wrappers in Beam, the SourceInputFormat for batch processing and the UnboundedSourceWrapper for stream processing.
ParDo
ParDo is the swiss army knife of Beam and can be compared to a RichFlatMapFunction in Flink with additional features such as SideInputs, SideOutputs, State and Timers. ParDo is essentially translated by the Flink runner using the FlinkDoFnFunction for batch processing or the FlinkStatefulDoFnFunction, while for streaming scenarios the translation is executed with the DoFnOperator that takes care of checkpointing and buffering of data during checkpoints, watermark emissions and maintenance of state and timers. This is all executed by Beam’s interface, called the DoFnRunner, that encapsulates Beam-specific execution logic, like retrieving state, executing state and timers, or reporting metrics.
Side Inputs
In addition to the main input, ParDo transforms can have a number of side inputs. A side input can be a static set of data that you want to have available at all parallel instances. However, it is more flexible than that. You can have keyed and even windowed side input which updates based on the window size. This is a very powerful concept which does not exist in Flink but is added on top of Flink using Beam.
AssignWindows
In Flink, windows are assigned by the WindowOperator when you use the window() in the API. In Beam, windows can be assigned at any point in time. Any element is implicitly part of a window. If no window is assigned explicitly, the element is part of the GlobalWindow. Window information is stored for each element in a wrapper called WindowedValue. The window information is only used once we issue a GroupByKey.
GroupByKey
Most of the time it is useful to partition the data by a key. In Flink, this is done via the keyBy() API call. In Beam the GroupByKey transform can only be applied if the input is of the form KV<Key, Value>. Unlike Flink where the key can even be nested inside the data, Beam enforces the key to always be explicit. The GroupByKey transform then groups the data by key and by window which is similar to what keyBy(..).window(..) would give us in Flink. Beam has its own set of libraries to do that because Beam has its own set of window functions and triggers. Essentially, GroupByKey is very similar to what the WindowOperator does in Flink.
Flatten
The Flatten operator takes multiple DataSet/DataStreams, called P[arallel]Collections in Beam, and combines them into one collection. This is equivalent to Flink’s union() operation.
The “Portable” Flink Runner in Beam
The portable Flink Runner in Beam is the evolution of the classic Runner. Classic Runners are tied to the JVM ecosystem, but the Beam community wanted to move past this and also execute Python, Go and other languages. This adds another dimension to Beam in terms of portability because, like previously mentioned, Beam already had portability across execution engines. It was necessary to change the translation logic of the Runner to be able to support language portability.
There are two important building blocks for portable Runners:
- A common pipeline format across all the languages: The Runner API
- A common interface during execution for the communication between the Runner and the code written in any language: The Fn API
The Runner API provides a universal representation of the pipeline as Protobuf which contains the transforms, types, and user code. Protobuf was chosen as the format because every language has libraries available for it. Similarly, for the execution part, Beam introduced the Fn API interface to handle the communication between the Runner/execution engine and the user code that may be written in a different language and executes in a different process. Fn API is pronounced “fun API”, you may guess why.
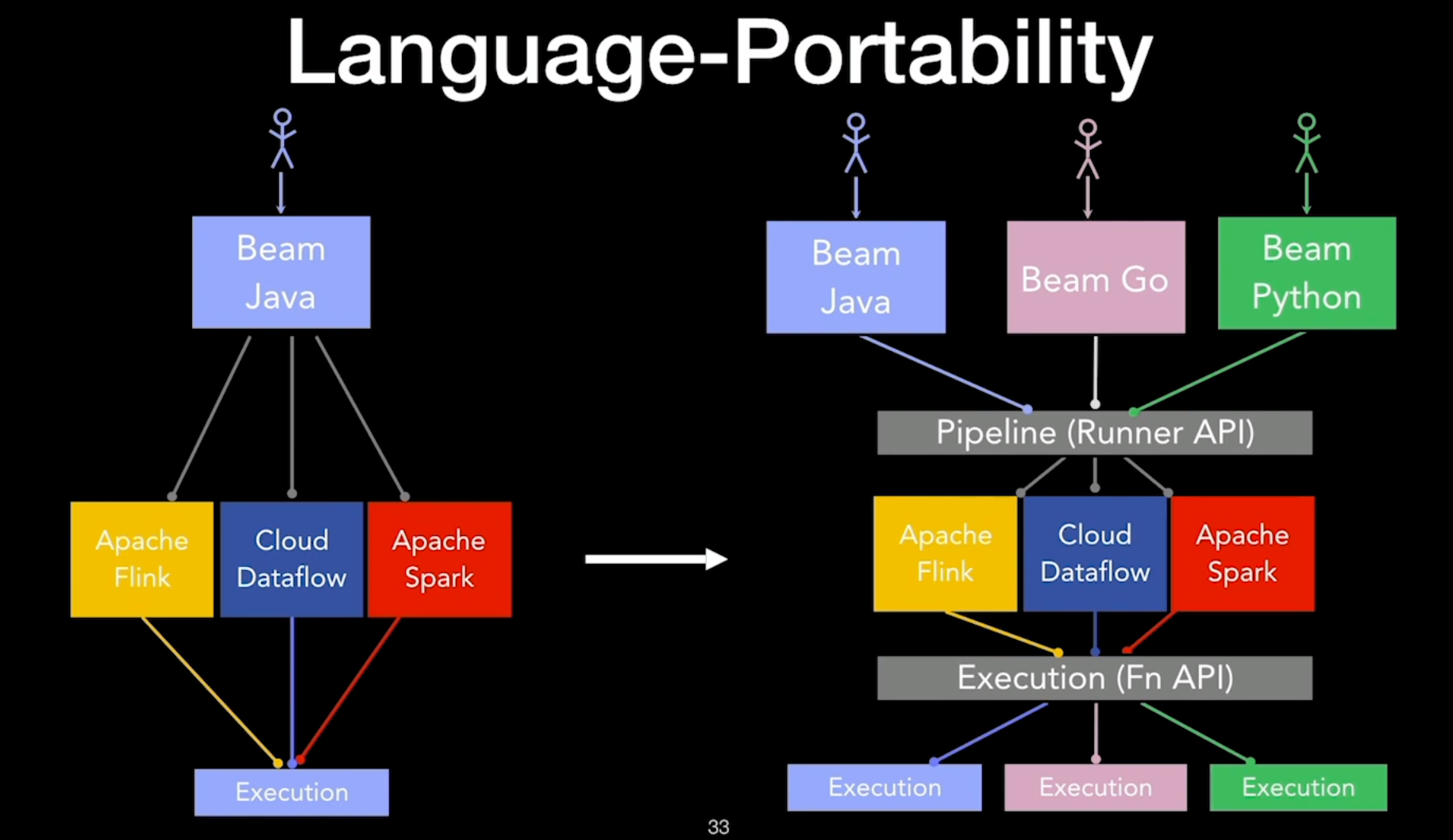
How Are Beam Programs Translated In Language Portability?
Users write their Beam pipelines in one language, but they may get executed in an environment based on a completely different language. How does that work? To explain that, let’s follow the lifecycle of a pipeline. Let’s suppose we use the Python SDK to write the pipeline. Before submitting the pipeline via the Job API to Beam’s JobServer, Beam would convert it to the Runner API, the language-agnostic format we described before. The JobServer is also a Beam component that handles the staging of the required dependencies during execution. The JobServer will then kick-off the translation which is similar to the classic Runner. However, an important change is the so-called ExecutableStage transform. It is essentially a ParDo transform that we already know but designed for holding language-dependent code. Beam tries to combine as many of these transforms into one “executable stage”. The result again is a Flink program which is then sent to the Flink cluster and executed there. The major difference compared to the classic Runner is that during execution we will start environments to execute the aforementioned ExecutableStages. The following environments are available:
- Docker-based (the default)
- Process-based (a simple process is started)
- Externally-provided (K8s or other schedulers)
- Embedded (intended for testing and only works with Java)
Environments hold the SDK Harness which is the code that handles the execution and the communication with the Runner over the Fn API. For example, when Flink executes Python code, it sends the data to the Python environment containing the Python SDK Harness. Sending data to an external process involves a minor overhead which we have measured to be 5-10% slower than the classic Java pipelines. However, Beam uses a fusion of transforms to execute as many transforms as possible in the same environment which share the same input or output. That’s why in real-world scenarios the overhead could be much lower.

Environments can be present for many languages. This opens up an entirely new type of pipelines: cross-language pipelines. In cross-language pipelines we can combine transforms of two or more languages, e.g. a machine learning pipeline with the feature generation written in Java and the learning written in Python. All this can be run on top of Flink.
Conclusion
Using Apache Beam with Apache Flink combines (a.) the power of Flink with (b.) the flexibility of Beam. All it takes to run Beam is a Flink cluster, which you may already have. Apache Beam’s fully-fledged Python API is probably the most compelling argument for using Beam with Flink, but the unified API which allows to “write-once” and “execute-anywhere” is also very appealing to Beam users. On top of this, features like side inputs and a rich connector ecosystem are also reasons why people like Beam.
With the introduction of schemas, a new format for handling type information, Beam is heading in a similar direction as Flink with its type system which is essential for the Table API or SQL. Speaking of, the next Flink release will include a Python version of the Table API which is based on the language portability of Beam. Looking ahead, the Beam community plans to extend the support for interactive programs like notebooks. TFX, which is built with Beam, is a very powerful way to solve many problems around training and validating machine learning models.
For many years, Beam and Flink have inspired and learned from each other. With the Python support being based on Beam in Flink, they only seem to come closer to each other. That’s all the better for the community, and also users have more options and functionality to choose from.